Pour pouvoir effectuer plus de tests corona plus rapidement et plus, il est possible de tester des échantillons en groupes au lieu de chaque échantillon individuellement. Un inconvénient de cette méthode est que plus de résultats sont des faux négatifs. Le chercheur et blogueur Jasper Verwilt (UGent) explique le dilemme.
Covid-19 est devenu une partie importante de leur vie quotidienne pour de nombreuses personnes depuis mars et a tué plus de 600 000 personnes. Pour augmenter la capacité de test, l'option de grouper les échantillons ("pooling") pour les tests est envisagée au lieu de tester chaque échantillon individuellement pour le coronavirus. C'est pratique et rapide, mais certains échantillons passent à travers le filet. En d'autres termes :certaines personnes atteintes de corona n'entendront pas cela.
Un prélèvement nasal est effectué pour tester les personnes pour le coronavirus. Cela signifie qu'un long bâton d'eau est tourné dans la cavité nasale pendant quelques secondes (ce n'est pas agréable), après quoi l'écouvillon est transporté vers un laboratoire de test. Un test RT-qPCR est généralement effectué en laboratoire. Il s'agit d'un test qui nous donne une idée du nombre de virus présents dans l'écouvillon. Plus d'un million de ces tests ont été réalisés en Belgique depuis le début de la pandémie de Covid-19. C'est beaucoup, mais si l'on veut suivre d'encore plus près la propagation du coronavirus, ce nombre devra augmenter très fortement. À ce stade, cependant, un problème important se pose :trop de tests, trop peu de temps, trop peu de réactif † Pour éviter cela, des laboratoires aux États-Unis et en Israël sont passés à ce que l'on appelle la "mise en commun † Ici, nous allons combiner plusieurs écouvillons — le nombre d'écouvillons par groupe peut varier — et te Nous avons sauvé tout le groupe d'un coup. L'idée est que si le virus est présent dans au moins un des écouvillons, le virus sera également présent dans le groupe, ce qui donnera alors un résultat positif. Seulement dans les groupes dont le test est positif, nous testons chaque échantillon individuellement, tandis que nous ne retestons pas et étiquetons les échantillons des groupes négatifs comme négatifs. Si nous voulons tester plus de personnes en Belgique pour le covid-19, la mutualisation semble être une bonne option à première vue.
Les deux stratégies les plus avancées par les chercheurs sont le regroupement 1D et 2D. Avec le pooling 1D, chaque échantillon est dans un pool, avec le pooling 2D, chaque échantillon est dans deux pools. La différence est plus évidente lorsque vous organisez les échantillons dans une matrice comme indiqué sur la figure.
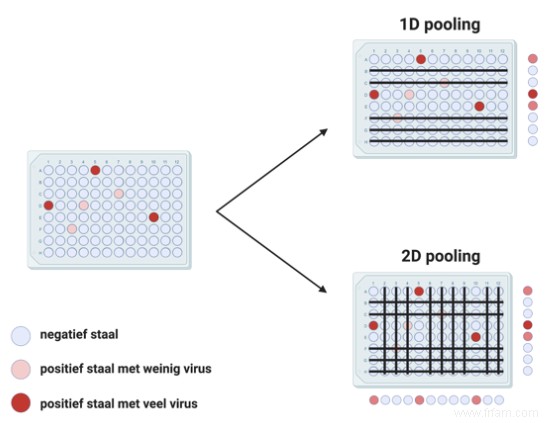
Les deux stratégies de regroupement sont très puissantes et peuvent rapidement réduire le nombre de tests à effectuer :le « regroupement » est plus efficace que les tests individuels. Si tout était si simple, bien sûr, tous les laboratoires du monde mettraient leurs écouvillons en commun. C'est loin de la situation actuelle et la raison en est les faux échantillons négatifs. Lorsque nous mettons en commun un écouvillon positif avec d'autres écouvillons négatifs, nous diluons l'échantillon positif. Celui-ci peut être tellement dilué que l'on ne trouve plus de virus dans le pool, alors qu'il était présent dans l'échantillon individuel. L'ensemble du pool est rejeté et tout le monde est informé que son test était négatif, y compris cette personne avec un écouvillon positif :un faux négatif. Cependant, cela se produit principalement si les échantillons contiennent peu de virus. Nous signalons généralement le nombre de faux négatifs comme "sensibilité † Ceci est calculé comme le nombre d'écouvillons positifs divisé par le nombre réel d'écouvillons positifs. Une sensibilité de 0,9 par exemple correspond à la présence de 10 % de faux négatifs.
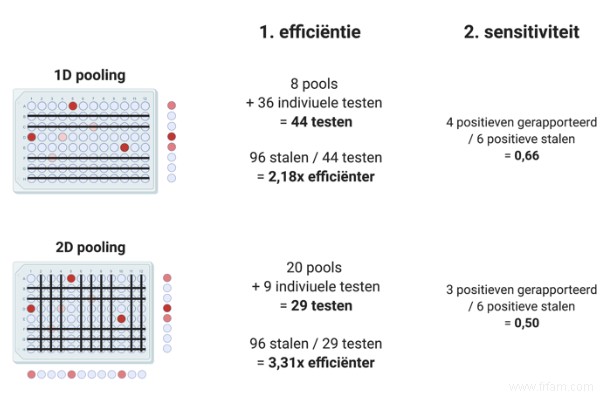
Dans la figure suivante, nous voyons un exemple de comment une stratégie plus efficace peut être moins sensible † Il semble y avoir une sorte de compromis entre les deux paramètres, soit :c'est l'un ou l'autre. Pour savoir comment ce compromis se comporte correctement avec un nombre variable d'échantillons positifs et différentes stratégies de regroupement, nous avons simulé de nombreuses situations différentes avec un programme informatique.
Nous avons simulé l'effet sur la sensibilité et l'efficacité des stratégies de regroupement pour des pourcentages variables d'échantillons positifs (prévalence ) de 0,01 à 10 %. La prévalence peut varier selon l'origine de l'échantillon. Les hôpitaux ont généralement une prévalence élevée, tandis que la plupart des tests des centres de soins pour bénéficiaires internes sont négatifs et la prévalence y est donc faible. Le test RT-qPCR est très sensible, nous supposons donc dans les simulations que si les échantillons sont testés individuellement, chaque échantillon positif sera trouvé.
On voit que si on voulait tester chaque Belge (on peut donc s'attendre à une faible prévalence), les grands pools 1D (12, 16 ou 24 échantillons) sont les plus efficaces. Il le problème est qu'à une prévalence aussi faible, la sensibilité de ces stratégies de mise en commun est problématiquement faible † Par exemple, pour un regroupement 1D avec 24 échantillons par groupe, nous déclarerions un échantillon positif sur quatre négatif. Alors peut-être vaut-il mieux renoncer à un peu d'efficacité pour un peu plus de sensibilité et se lancer dans des pools de quatre échantillons ? C'est le compromis dont j'ai parlé plus tôt.
Pourquoi est-ce que la sensibilité des stratégies de mutualisation avec de grands pools dépend tellement de la prévalence ? Lorsqu'il y a très peu d'échantillons positifs et qu'il y a un échantillon positif dans un pool, il y a peu de chance qu'il y ait un deuxième échantillon positif dans le pool. Un échantillon est dilué par tous les échantillons négatifs et est perdu dans l'analyse. D'un autre côté, s'il y a de nombreux échantillons positifs, il y a presque toujours plus d'un échantillon positif dans un pool, de sorte que le pool est généralement également positif. La prévalence est donc d'une grande importance, mais comment la calcule-t-on ? En testant les échantillons. Mais avant de tester, nous devons connaître la prévalence pour déterminer la bonne stratégie. Voyez-vous le problème? De cette façon, nous pouvons continuer à tourner en rond.
Faut-il commencer à mutualiser les tests covid-19 prochainement ? Comme vous l'avez peut-être lu, c'est une question difficile à laquelle nous ne pouvons malheureusement pas encore répondre. Le pooling est une astuce très puissante pour analyser rapidement un grand nombre d'échantillons, mais on passera forcément à côté de quelques échantillons positifs (surtout à faible prévalence). D'ailleurs, c'est le cas de nombreux tests. Que nous puissions nous permettre cela si nous voulons tester l'ensemble de la population pour le corona est une considération importante que je n'ai heureusement pas à prendre en compte.
Nous avons mis nos résultats en ligne sous forme de prépublication. Il doit faire l'objet d'un examen par les pairs avant d'être publié. Lors de l'examen par les pairs, l'article est soigneusement corrigé et les auteurs de l'article sont souvent invités à faire des ajustements. Il est important de savoir que cela ne s'est pas encore produit ici. Une prépublication doit toujours être lue avec un œil critique.
